چشم انداز کامپیوتری -سفری از CNN به Mask R -CNN و YOLO -Part 2
چشم انداز کامپیوتری -سفری از CNN به Mask R -CNN و YOLO -Part 2
این دومین مقاله از این سری است که به کشف و درک معماری و عملکرد YOLO (شما فقط یکبار نگاه می کنید ).
برای درک دقیق الگوریتم های بینایی رایانه در CNN ، CNN مبتنی بر منطقه (R-CNN) ، سریع R-CNN ، سریعتر R-CNN کلیک کنید. این قسمت 1 است.
در مقاله بعدی ، کد YOLO v3

YOLO- شما فقط یکبار نگاه می کنید پاسخ الگوریتم های بهتر ، سریعتر و دقیق بینایی رایانه است.
ویژگی های YOLO
کار YOLO
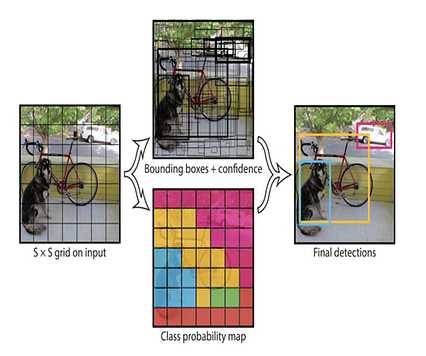 شما فقط یکبار نگاه می کنید-YOLO
شما فقط یکبار نگاه می کنید-YOLO درک خروجی YOLO
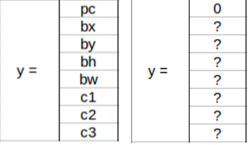 < /img>
< /img> بعد خروجی چقدر خواهد بود؟
تقسیم تصویر به یک شبکه S × S.
هر سلول شبکه جعبه های محدود کننده B ، اطمینان برای آن جعبه ها و احتمالات کلاس C را پیش بینی می کند.
هر کادر محدود کننده شامل 5 پیش بینی است: bx ، by ، bw ، bh و اعتماد
بعد خروجی S × S × (B ∗ (1 + 4) + C) تنسور
به عنوان مثال ، اگر تصویر را به یک شبکه 7 7 7 و هر کدام تقسیم کنیم سلول شبکه 2 جعبه محدود را پیش بینی می کند و ما 20 کلاس دارای برچسب داریم ، در این صورت خروجی 7 x 7 x (2*5+20) = 7 x 7 x 30 تنسور
IoU بین مرز حقیقت زمین چیست جعبه و کادر محدود کننده پیش بینی شده؟
تقاطع بر روی اتحادیه - IoU
IoU تقاطع را بر روی اتحاد دو جعبه محدود کننده ، جعبه محدود کننده برای حقیقت زمین و جعبه محدود کننده برای کادر پیش بینی شده توسط الگوریتم

وقتی IoU 1 است ، این بدان معناست که پیش بینی شده و زمین- جعبه های محدود کننده حقیقت کاملاً با هم تداخل دارند. بیشتر از 0.5؟
سرکوب غیر حداکثر
سرکوب کنید. برای مثال ، اگر سه مستطیل با 0.6 و 0.7 و 0.9 داشته باشیم. برای شناسایی IoU وسیله نقلیه در تصویر زیر ، Non-Max Suppression جعبه محدوده را با IoU 0.9 نگه می دارد و جعبه های محدود کننده باقی مانده 0.6 و 0.7 IoU را سرکوب می کند.
برای خودرو در تصویر زیر ، Non-Max Suppression IoU را با 0.8 نگه می دارد و جعبه محدود IoU را با 0.7

طراحی شبکه YOLO v1
معماری شبکه YOLO با الهام از مدل GoogLeNet برای طبقه بندی تصویر
شبکه تشخیص YOLO دارای 24 لایه متحرک دنبال شده است توسط 2 لایه کاملاً متصل شده. لایه ها از لایه های قبلی فاصله دارند. تشخیص

YOLO از یک تابع فعال سازی خطی برای لایه نهایی و ReLU نشتی برای تمام لایه های دیگر.
YOLO مختصات جعبه های محدود کننده را مستقیماً با استفاده از لایه های کاملاً متصل به هم در بالای استخراج کننده ویژگی های پیچشی پیش بینی می کند. YOLO فقط 98 جعبه در هر تصویر را پیش بینی می کند.
نقاط قوت YOLO
محدودیت های YOLO
انواع دیگر YOLO
Fast YOLO
Fast YOLO یک نوع سریع از یولو از 9 لایه کانولوشن به جای 24 مورد استفاده در YOLO استفاده می کند و همچنین از فیلترهای تب استفاده می کند.
اندازه شبکه بین YOLO و Fast YOLO متفاوت است اما همه پارامترهای آموزش و آزمایش بین YOLO و Fast YOLO یکسان است.
خروجی نهایی شبکه ما تنسور 7 × 7 × 30 پیش بینی است.
YOLOv2 یا YOLO9000
Anchor box یا Prior چیست و چه کمکی به آن می کند؟
Anchor Boxs یا Priors
از جعبه های لنگر برای تشخیص اجسام متعدد ، اشیاء با مقیاس های مختلف استفاده می شود ، و اجسام همپوشان این باعث افزایش سرعت و کارایی برای تشخیص شی می شود.
جعبه های لنگر همه پیش بینی های شی را یکجا ارزیابی می کنند و نیازی به اسکن تصویر با استفاده از یک پنجره کشویی ندارید
جعبه های لنگر مجموعه ای از پیش تعیین شده هستند جعبه های محدود کننده با ارتفاع و عرض مشخص. این کادرها به گونه ای تعریف شده اند که مقیاس و نسبت ابعاد کلاسهای شیء خاصی را که می خواهید تشخیص دهید ، ثبت کنید.
YOLOv2 کل تصویر را به 13 سلول شبکه 13 X 13 تقسیم می کند. YOLOv2 خوشه بندی k-means را بر روی ابعاد جعبه های محدود کننده اجرا می کند تا پیشرو یا لنگرهای خوبی برای مدل بدست آورد. YOLOv2 در بر داشت k = 5 عملکرد بهتری را ارائه می دهد.
 Red is Ground Truth. جعبه های آبی 5 جعبه لنگر
Red is Ground Truth. جعبه های آبی 5 جعبه لنگر برای پیش بینی چندین اشیاء در یک تصویر ، YOLOv2 هزاران پیش بینی می کند. تشخیص شیء نهایی با حذف جعبه های لنگر که متعلق به کلاس پس زمینه است انجام می شود و بقیه با نمره اطمینان آنها فیلتر می شود. ما جعبه های لنگر را با IoU بزرگتر از 0.5 می یابیم. جعبه های لنگر با بیشترین نمره اطمینان با استفاده از سرکوب Non-Max که قبلاً توضیح داده شد ، انتخاب می شوند.
YOLOv3
کد YOLO v3 است که در مقاله بعدی
منابع:
https://pjreddie.com/media/files/papers/yolo.pdf
https://arxiv.org/pdf/1612.08242. pdf
https://pjreddie.com/media/files/papers/YOLOv3.pdf
http://deeplearning.csail.mit.edu/instance_ross.pdf


























